
SQLD 단원별 목록으로
1. 반정규화를 통한 성능향상 전략
가) 반정규화의 정의
- 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발과 운영의 단순화를 위해 중복,통합,분리 등을 수행하는 데이터 모델링 기법
- 데이터 무결성이 깨질 수 있는 위험을 무릅쓰고 데이터를 중복하여 반정규화를 적용하는 이유는 데이터를 조회할 때 디스크 I/O량이 많아 성능이 저하되거나 경로가 너무 멀어 조 인으로 인한 성능저하가 예상되거나 칼럼을 계산하여 읽을 때 성능이 저하될 것이 예상되는
경우 반정규화를 수행하게 된다.

나) 반정규화의 적용방법
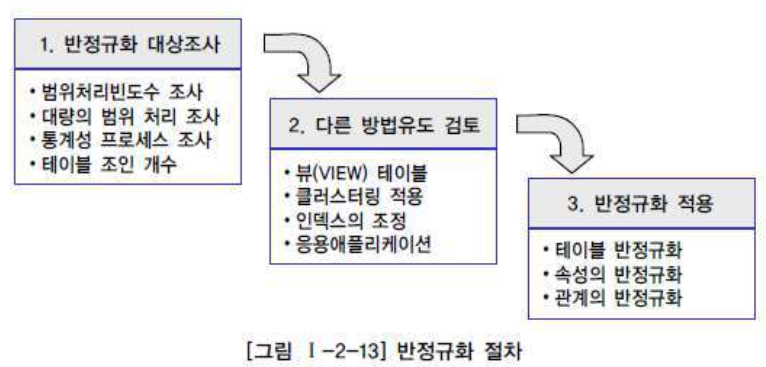
· 반정규화의 대상 조사
- 자주 사용되는 테이블에 접근(Access)하는 프로세스의 수가 많고 항상 일정한 범위만 을 조회하는 경우.
- 대량의 데이터가 있고 대량의 데이터 범위를 자주 처리하는 경우 처리범위를 일정하게 줄이지 않으면 성능을 보장할 수 없을 경우.
- 통계성 프로세스에 의해 통계 정보를 필요로 할 때 별도의 통계테이블(반정규화 테이블)을 생성.
- 테이블에 지나치게 많은 조인(JOIN)이 걸려 데이터를 조회하는 작업이 기술적으로 어려울 경우.
· 반정규화의 대상에 대해 다른 방법으로 처리할 수 있는지 검토
- 지나치게 많은 조인(JOIN)이 걸려 데이터를 조회하는 작업이 기술적으로 어려울 경우 뷰(VIEW)를 사용하면 이를 해결할 수도 있다.
- 대량의 데이터처리나 부분처리에 의해 성능이 저하되는 경우에 클러스터링을 적용하거나 인덱스를 조정함으로써 성능을 향상할 수
있다. 클러스터링을 적용하는 방법은 대량의 데이터를 특정 클러스터링 팩트에 의해 저장방식을 다르게 하는 방법이다.
- 대량의 데이터는 Primary Key의 성격에 따라 부분적인 테이블로 분리할 수 있다. 즉 파티셔닝 기법(Partitioning)이 적용되어
성능저하를 방지할 수 있다.
- 응용 애플리케이션에서 로직을 구사하는 방법을 변경함으로써 성능을 향상시킬 수 있다.
· 반정규화를 적용한다.
- 반정규화를 하는 대상으로는 테이블, 속성, 관계에 대해 적용할 수 있으며 꼭 테이블과 속성, 관계에 대해 중복으로 가져가는 방법만이
반정규화가 아니고 테이블, 속성, 관계를 추가할 수도 있고 분할할 수도 있으며 제거할 수도 있다.
2. 반정규화의 기법
가) 테이블의 반정규화
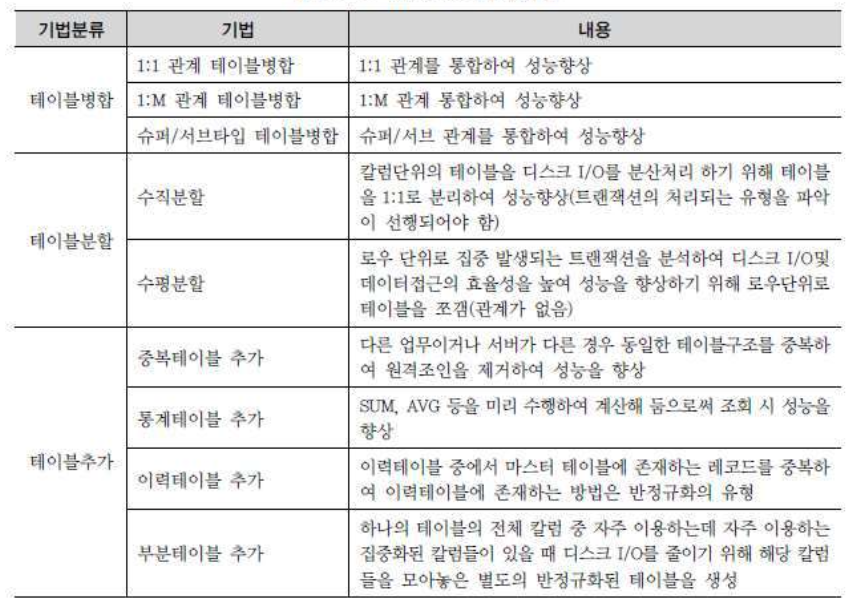
나) 칼럼 반정규화

다) 관계 반정규화

3. 정규화가 잘 정의된 데이터 모델에서 성능이 저하될 수 있는 경우 ①

- 공급자와 전화번호, 메일주소, 위치는 1:M 관계이므로 한 명의 공급자당 여러 개의 전화번호, 메일주소, 위치가 존재한다.
따라서 가장 최근에 변경된 값을 가져오기 위해서는 조금 복잡한 조인이 발생될 수 밖에 없다.
SELECT A.공급자명, B.전화번호, C.메일주소, D.위치
FROM 공급자 A,
(SELECT X.공급자번호, X.전화번호
FROM 전화번호 X,
(SELECT 공급자번호, MAX(순번) 순번
FROM 전화번호
WHERE 공급자번호 BETWEEN '1001' AND '1005'
GROUP BY 공급자번호) Y
WHERE X.공급자번호 = Y.공급자번호
AND X.순번 = Y.순번) B,
(SELECT X.공급자번호, X.메일주소
FROM 메일주소 X,
(SELECT 공급자번호, MAX(순번)
FROM 메일주소
WHERE 공급자번호 BETWEEN
GROUP BY 공급자번호) Y
WHERE X.공급자번호 = Y.공급자번호
AND X.순번 = Y.순번) C,
(SELECT X.공급자번호, X.위치
FROM 위치 X,
(SELECT 공급자번호, MAX(순번)
FROM 위치
WHERE 공급자번호 BETWEEN '1001' AND '1005'
GROUP BY 공급자번호) Y
WHERE X.공급자번호 = Y.공급자번호
AND X.순번 = Y.순번) D
WHERE A.공급자번호 = B.공급자번호
AND A.공급자번호 = C.공급자번호
AND A.공급자번호 = D.공급자번호
BETWEEN '1001' AND '1005'
AND A.공급자번호 BETWEEN '1001' AND '1005'- 정규화 된 모델이 적절하게 반정규화 되지 않으면 위와 같은 복잡한 SQL구문은 쉽게 나 올 수 있다.


- 위에서 복잡하게 작성된 SQL문장이 반정규화를 적용하므로 인해 다음과 같이 간단하게 작성이 되어 가독성도 높아지고 성능도 향상되어 나타났다.
4. 정규화가 잘 정의된 데이터 모델에서 성능이 저하된 경우 ②
- 업무의 영역이 커지고 다른 업무와 인터페이스가 많아짐에 따라 데이터베이스서버가 여 러 대인 경우

- 서버 A에 부서와 접수 테이블이 있고 서버 B에 연계라는 테이블이 있는데 서버 B에서 데이터를 조회할 때 빈번하게 조회되는 부서번호가 서버 A에 존재하기 때문에 연계, 접수, 부서 테이블이 모두 조인이 걸리게 된다. 게다가 분산데이터베이스 환경이기 때문에 다른 서버
간에 조인이 걸리게 되어 성능이 저하가 된다.



- 위의 분산 환경에 따른 데이터 모델을 다음과 같이 서버A에 있는 부서테이블의 부서명을 서버 B의 연계테이블에 부서명으로 속성
반정규화를 함으로써 조회 성능을 향상시킬 수 있다.
'자격증 > SQL개발자(SQLD)' 카테고리의 다른 글
| 2-5장. 데이터 모델과 성능_데이터베이스 구조와 성능 (1) | 2023.05.20 |
|---|---|
| 2-4장. 데이터 모델과 성능_대량 데이터에 따른 성능 (9) | 2023.05.18 |
| 2-2장. 데이터 모델과 성능_정규화와 성능 (9) | 2023.05.17 |
| 2-1장. 데이터 모델과 성능_성능 데이터 모델링의 개요 (8) | 2023.05.16 |
| 1-5장. 데이터 모델링의 이해_식별자(Identifiers) (6) | 2023.05.14 |



