2-4장. 데이터 모델과 성능_대량 데이터에 따른 성능

SQLD 단원별 목록으로
1. 대량 데이터발생에 따른 테이블 분할 개요
- 대량의 데이터가 하나의 테이블에 집약되어 있고 하나의 하드웨어 공간에 저장되어 있으면 성능저하를 피하기가 힘들다.
- 하나의 테이블에 대량의 데이터가 존재하는 경우에는 인덱스의 Tree구조가 너무 커져 효율성이 떨어져 데이터를 처리
(입력, 수정, 삭제, 조회)할 때 디스크 I/O를 많이 유발하게 된다.
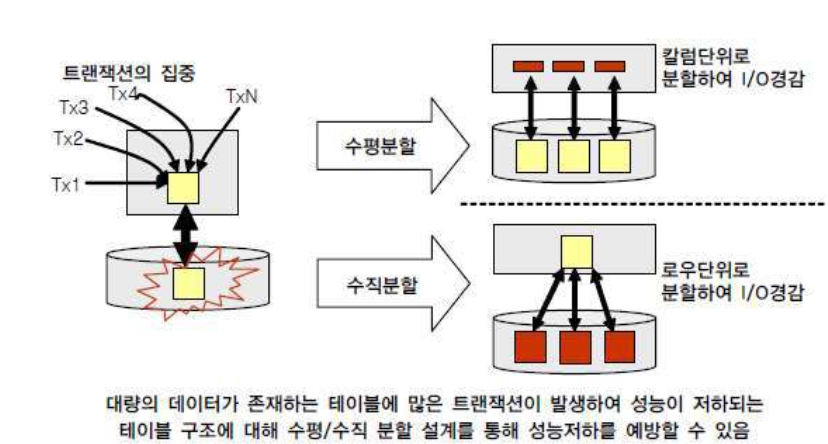
- 칼럼이 많아지게 되면 물리적인 디스크에 여러 블록에 데이터가 저장되게 된다. 따라서 데이터를 처리할 때 여러 블록에서 데이터를
I/O해야 하는 즉 SQL문장의 성능이 저하될 수 특징을 가지게 된다.

- 로우 길이가 너무 길어서 데이터 블록 하나에 데이터가 모두 저장되지 않고 두 개 이상의 블록에 걸쳐 하나의 로우가 저장되어 있는
형태가 로우체이닝(Row Chaining) 현상이다.
2. 한 테이블에 많은 수의 칼럼을 가지고 있는 경우

- 칼럼의 앞쪽에 위치한 발행기관명, 수량, 중간에 위치한 공고일, 발행일에 대한 정보를 가져오려면 물리적으로 칼럼의 값이 블록에 넓게 산재되어 있어 디스크 I/O가 많이 일어나게 된다.

- 많은 칼럼을 가지고 있는 테이블에 대해서는 트랜잭션이 발생될 때 어떤 칼럼에 대해 집중적으로 발생하는지 분석하여 테이블을 쪼개어
주면 디스크 I/O가 감소하게 되어 성능이 개선되게 된다.
- 많은 수의 칼럼을 가지는 데이터 모델 형식도 실전 프로젝트에서 흔히 나타나는 현상이 다. 트랜잭션을 분석하여 적절하게 1:1 관계로
분리함으로써 성능향상이 가능하도록 해야 한다.
3. 대량 데이터 저장 및 처리로 인해 성능
- 테이블에 많은 양의 데이터가 예상될 경우 파티셔닝을 적용하거나 PK에 의해 테이블을 분할하는 방법을 적용할 수 있다.
- Oracle의 경우 크게 LIST PARTITION(특정값 지정), RANGE PARTITION(범위), HASH PARTITION(해쉬적용),
COMPOSITE PARTITION(범위와 해쉬가 복합) 등이 가능하다.
가) RANGE PARTITION 적용

- DBMS 내부적으로 SQL WHERE 절에 비교된 요금일자에 의해 각 파티션에 있는 정보를 찾아가므로 평균 1,000만 건의 데이터가 있는 곳을 찾아도 되어 성능이 개선될 수 있다.
- RANGE PARTITION은 데이터 보관주기에 따라 테이블에 데이터를 쉽게 지우는 것이 가능하므로(파티션 테이블을 DROP하면 되므로) 데이터보관주기에 다른 테이블관리가 용이하다.
나) LIST PARTITION 적용
- 지점, 사업소, 사업장, 핵심적인 코드값 등으로 PK가 구성되어 있고 대량의 데이터가 있 는 테이블이라면 값 각각에 의해 파티셔닝이 되는 LIST PARTITION을 적용할 수 있다.

- LIST PARTITION은 대용량 데이터를 특정값에 따라 분리 저장할 수는 있으나 RANGE PARTITION과 같이 데이터 보관주기에 따라
쉽게 삭제하는 기능은 제공될 수 없다.
다) HASH PARTITION
- 지정된 HASH 조건에 따라 해쉬 알고리즘이 적용되어 테이블이 분리되며 설계자는 테이블에 데이터가 정확하게 어떻게 들어갔는지 알 수 없다. 역시 성능향상을 위해 사용하며 데이터 보관주기에 따라 쉽게 삭제하는 기능은 제공될 수 없다.
4. 테이블에 대한 수평분할/수직분할의 절차
① 데이터 모델링을 완성
② 데이터베이스 용량산정
③ 대량 데이터가 처리되는 테이블에 대해 트랜잭션 처리 패턴을 분석
④ 칼럼 단위로 집중화된 처리가 발생하는지, 로우단위로 집중화된 처리가 발생되는지 분석하여 집중화된 단위로 테이블 분리를 검토